Ontology Architecture of the oeGOV Ontologies
An Ontology Architecture should be designed to maximize reuse and minimize impacts from changes. In keeping with best practices, the component ontology is based on the following organizing principles:
- defining domain boundaries based on ease-of-evolution and governance;
- organizing Named Graphs according to levels of specificity;
- isolating reusable constructs in foundation ontologies;
- distinguishing different types of Named Graphs;
- confoming to consistent Naming and Identifier Rules.
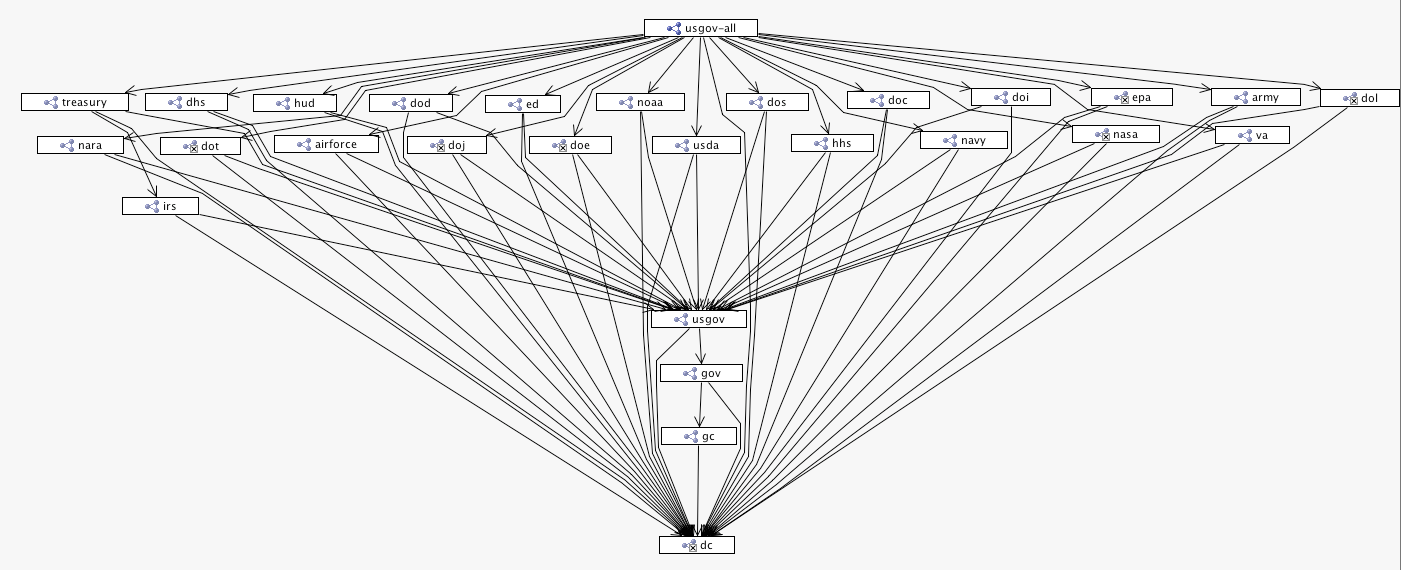
oeGOV is made up of a number of OWL schemas and datasets published as N3 files. Each file is called a ‘Named Graph’ that holds OWL resources across a number of ontology domains.
Each US Agency is a separate Named Graph that imports a common foundation ontology ‘usgov-bodies.n3′. This establishes the existence of many government bodies but without defining the internal organization of an agency, An example of an Agency Named Graph is ‘us1gov_dhs.n3′. The ’1′ after ‘us’ in the name denotes that the dataset is a level 1 dataset. More specific datasets carry progressively higher numbers.
The ‘usgov-bodies.n3′ ontology imports ‘oegov.n3′ – an ontology that defines the basic organizational structure of a democratic government.
The following figure illustrates the oeGOV Ontology Architecture. Each box is a Named Graph and the connections are ‘import’ relationships. The topmost Named Graph is an aggregation Named Graph that imports each Named Graph of the US Government Agencies. These in turn import the common Named Graph, as discussed before.
The oeGOV ontologies will be published on August 1, 2009.
You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.